Web 크롤링/Python Crawling
[크롤링기초] 다나와 로그인 스크래핑 예제
Link2Me
2021. 6. 25. 18:44
728x90
다나와 사이트 로그인 후 로그인된 상태에서만 가져올 수 있는 정보를 보여주는 예제이다.
먼저, 로그인을 위해 알아야 할 사항이다.
크롬브라우저에서 F12 를 눌러 Network 에서 2번 항목을 체크하자.
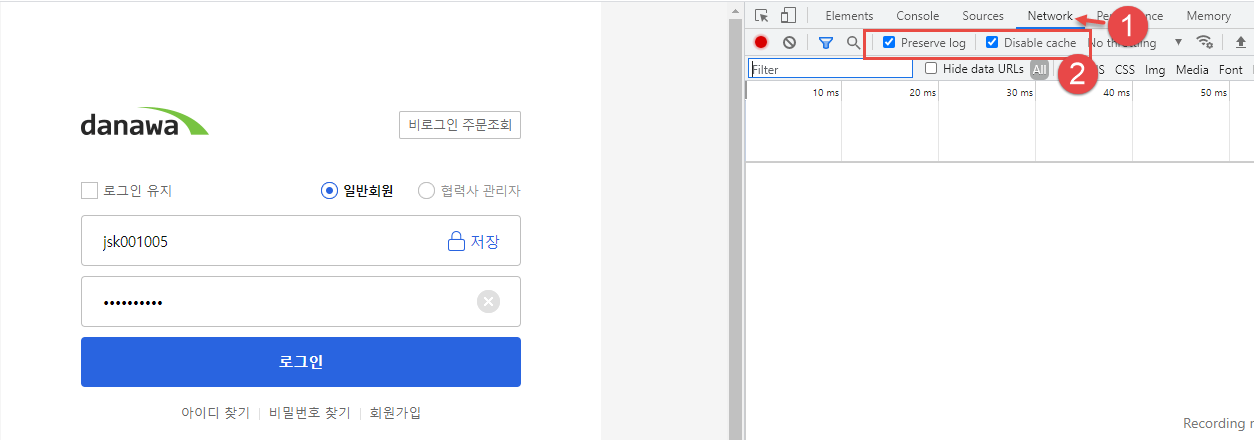
브라우저에서 접속한 것처럼 하려면 4번과 5번 정보가 매우 중요하다.
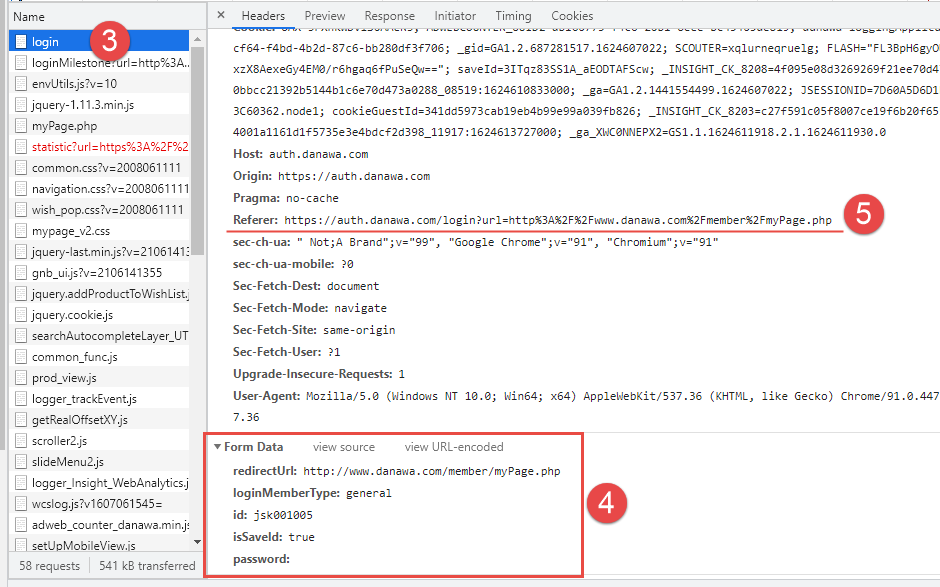
로그인 URL 정보
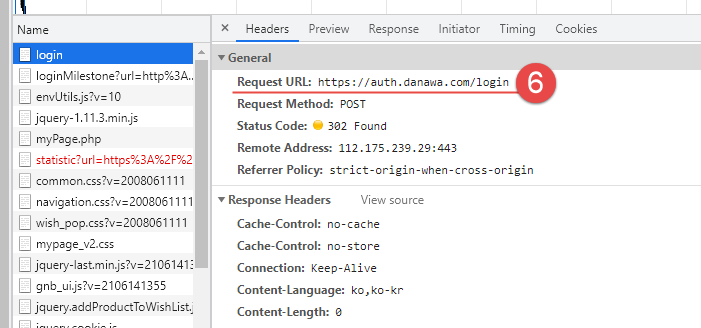
이제 로그인이 잘 된 것인지 확인하는 과정이다.
로그인 후에만 볼 수 있는 주문/배송 내역 조회 내역을 가져오는 스크래핑 방법이다.

로그인 성공 후 세션정보를 가지고 이동할 폐이지를 "주문/배송 조회"로 스크래핑 범위 한정해서 해보자.
li 태그에서 마우스 우클릭을 하고 Copy Selector 을 선택하면 해당 정보를 반환한다.
#wrap_shop_danawa > div.my_wish_bg > div > div.wish_content_wrap > div.my_info.no_sub_info > div > ul > li:nth-child(1)
를 반환하는데 여기에서 div.my_info.no_sub_info > div > ul > li 가 필요로 하는 것이라는 걸 알 수 있다.


로그인 성공 여부를 간단하게 확인하는 방법은 로그인 후 ID 정보가 있는지 확인하는 것이 가장 쉬운 방법이다.

파이썬 소스 코드 작성
화면에서도 결과를 출력하여 확인하고, 파일로도 저장해서 결과를 확인해 본다.
|
# BeautifulSoup은 HTML 과 XML 파일로부터 데이터를 수집하는 라이브러리
# pip install bs4
# pip install requests
# pip install fake-useragent
from bs4 import BeautifulSoup
import requests as req
from fake_useragent import UserAgent
import csv
# 로그인 정보(개발자 도구)
login_info = {
'redirectUrl': 'http://www.danawa.com/member/myPage.php',
'loginMemberType': 'general',
'id': 'jsk001005',
'isSaveId': 'true',
'password': ''
}
# 헤더 정보
headers = {
'User-agent': UserAgent().chrome,
'Referer' : 'https://auth.danawa.com/login?url=http%3A%2F%2Fwww.danawa.com%2Fmember%2FmyPage.php'
}
# 로그인 URL
baseUrl = 'https://auth.danawa.com/login'
with req.session() as s:
# Request(로그인 시도)
res = s.post(baseUrl, login_info, headers=headers)
# 로그인 시도 실패시 예외
if res.status_code != 200:
raise Exception("Login failed.")
# 본문 수신 데이터 확인
# print(res.content.decode('UTF-8'))
# 로그인 성공 후 세션 정보를 가지고 페이지 이동
res = s.get('https://buyer.danawa.com/order/Order/orderList', headers=headers)
# 페이지 이동 후 수신 데이터 확인
# print(res.text)
# bs4 초기화
soup = BeautifulSoup(res.text,"html.parser")
# 로그인 성공 여부 체크
check_name = soup.find('p', class_='user')
# print(check_name)
# 선택자 사용
info_list = soup.select('div.my_info.no_sub_info > div > ul > li')
# print(info_list) # 확인
# 제목
print()
print('-' * 50)
myshoppingList = []
for v in info_list:
# 속성 메소드 확인
# print(dir(v))
# 필요한 텍스트 추출
proc, val = v.find('span').string.strip(), v.find('strong').string.strip()
print('{} : {}'.format(proc,val))
# 파일 저장 목적 변수에 저장
temp = []
temp.append(v.find('span').string.strip())
temp.append(v.find('strong').string.strip())
myshoppingList.append(temp)
print('-' * 50)
with open('myshoppingList.csv',"w", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
writer.writerows(myshoppingList)
print('CSV File created!')
f.close
|
테스트에 사용한 파이썬 소스 코드
728x90