파이썬 selenium 으로 다나와 제품 리스트 크롤링
다나와(https://www.danawa.co.kr) 사이트 제품 검색에서 원하는 것만 필터링해서 해당 제품 리스트를 크롤링하는 예제이다.
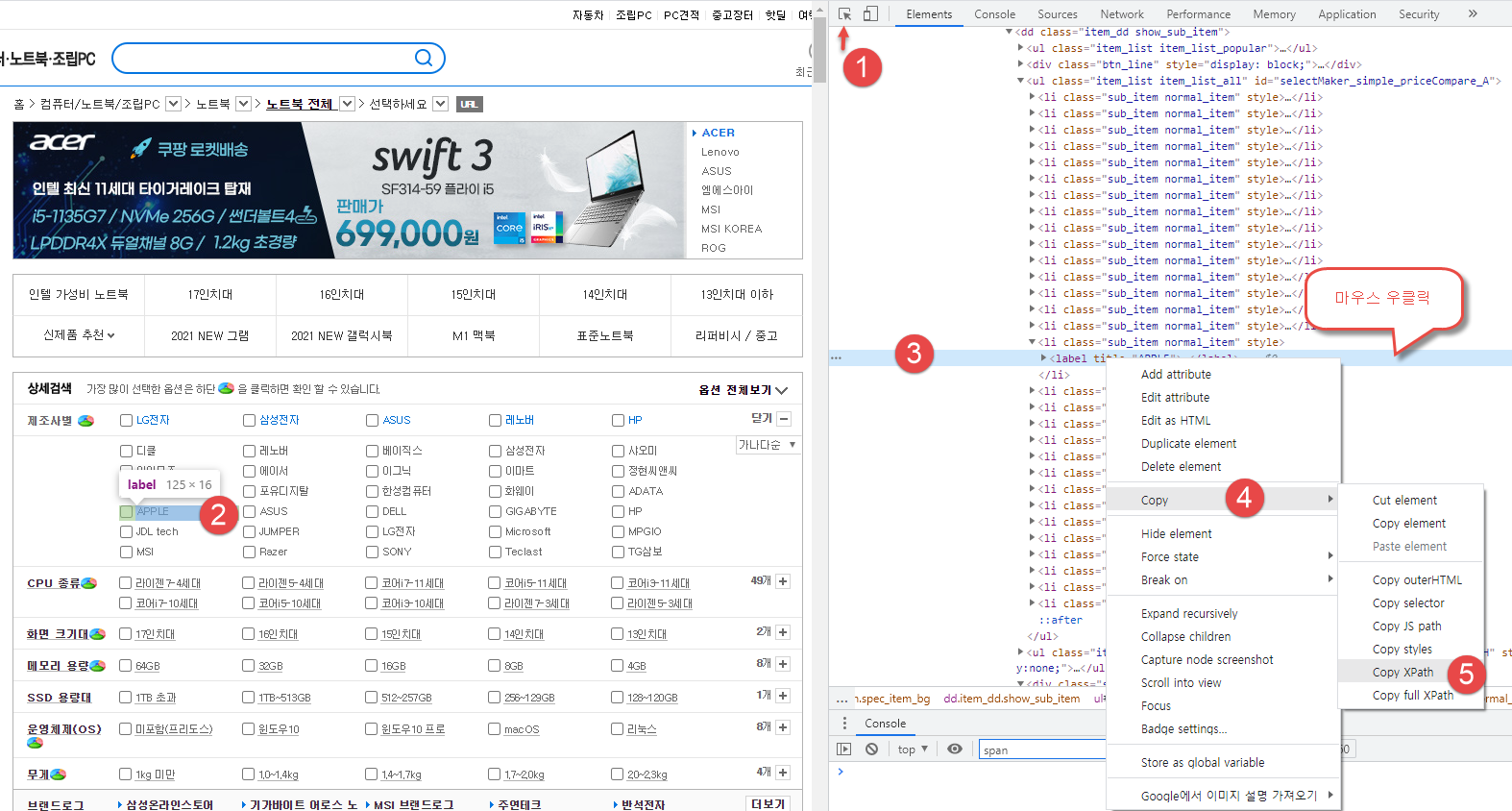
제조사별 검색
APPLE 을 보기 위해서는 우측에 + 버튼을 눌러야 보인다.
5번 Copy XPath 로 얻는 결과는 //*[@id="dlMaker_simple"]/dd/div[2]/button[1]
WebDriverWait(driver,3).until(EC.presence_of_element_located((By.XPATH,'//*[@id="dlMaker_simple"]/dd/div[2]/button[1]'))).click()

특정 제품 선택하여 제품 리스트 선택
동일한 방법으로 XPath 를 얻어서 붙이면 된다.
WebDriverWait(driver,2).until(EC.presence_of_element_located((By.XPATH,'//*[@id="selectMaker_simple_priceCompare_A"]/li[16]/label'))).click()
여기서 APPLE 은 16번째에 있는 걸 확인할 수 있다.
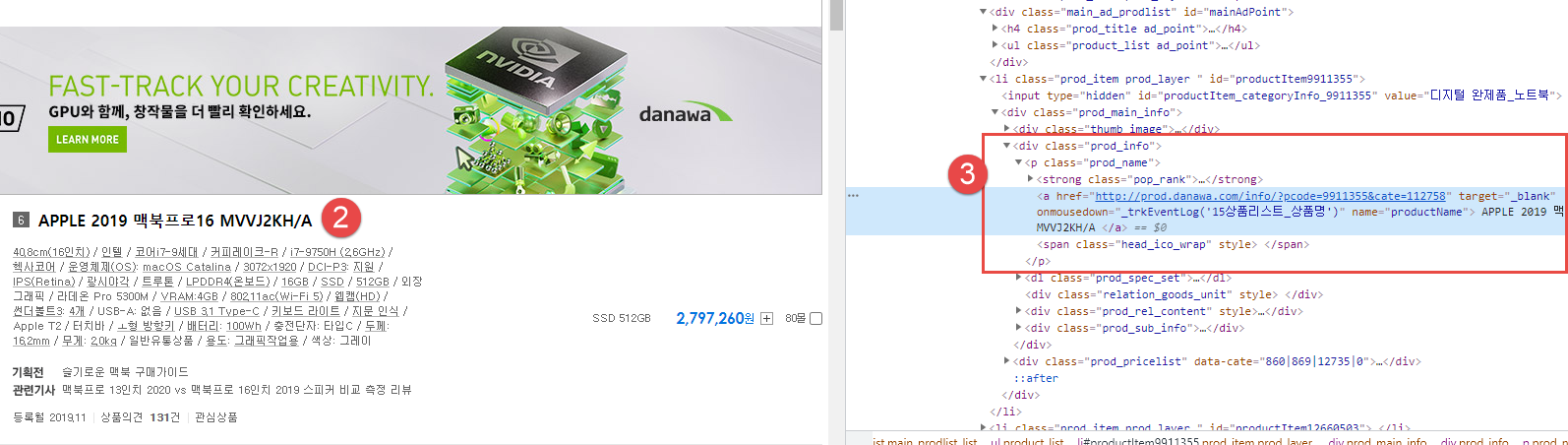
APPLE 제품 정보 중에서 상품명, 가격, 이미지 링크만 크롤링하는 방법
번호 순서대로 살펴보면 금방 원하는 정보가 어떤 것인지 확인할 수 있다.
li 태그 중에서 class 가 prod_item.prod_layer 인 것 전부를 크롤링하면 된다는 걸 알아내는 것이 매우 중요하다.
goods_list = soup.select('li.prod_item.prod_layer')

제품정보 크롤링
ㅇ 상품 모델명
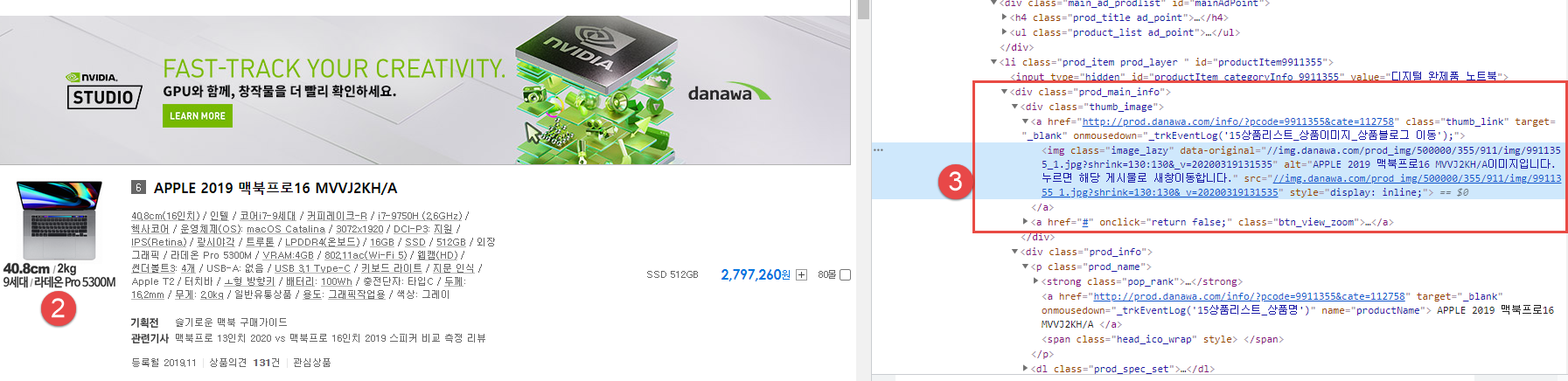
제품 가격

제품 이미지 경로
파이썬 코드
|
# pip install selenium
# pip install chromedriver-autoinstaller
# pip install bs4
from selenium import webdriver
import chromedriver_autoinstaller
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
import time
# 다나와 사이트 검색
options = Options()
options.add_argument('headless'); # headless는 화면이나 페이지 이동을 표시하지 않고 동작하는 모드
# webdirver 설정(Chrome, Firefox 등)
chromedriver_autoinstaller.install()
driver = webdriver.Chrome(options=options) # 브라우저 창 안보이기
# driver = webdriver.Chrome() # 브라우저 창 보이기
# 크롬 브라우저 내부 대기 (암묵적 대기)
driver.implicitly_wait(5)
# 브라우저 사이즈
driver.set_window_size(1920,1280)
# 페이지 이동(열고 싶은 URL)
driver.get('http://prod.danawa.com/list/?cate=112758&15main_11_02')
# 페이지 내용
# print('Page Contents : {}'.format(driver.page_source))
# 제조사별 검색 (XPATH 경로 찾는 방법은 이미지 참조)
WebDriverWait(driver,3).until(EC.presence_of_element_located((By.XPATH,'//*[@id="dlMaker_simple"]/dd/div[2]/button[1]'))).click()
# 원하는 모델 카테고리 클릭 (XPATH 경로 찾는 방법은 이미지 참조)
WebDriverWait(driver,2).until(EC.presence_of_element_located((By.XPATH,'//*[@id="selectMaker_simple_priceCompare_A"]/li[16]/label'))).click()
# 2차 페이지 내용
# print('After Page Contents : {}'.format(driver.page_source))
# 검색 결과가 렌더링 될 때까지 잠시 대기
time.sleep(2)
#bs4 초기화
soup = BeautifulSoup(driver.page_source, 'html.parser')
# 소스코드 정리
# print(soup.prettify())
# 상품 리스트 선택
# goods_list = soup.select('div.main_prodlist.main_prodlist_list > ul > li')
goods_list = soup.select('li.prod_item.prod_layer')
# 상품 리스트 확인
# print(goods_list)
for v in goods_list:
if v.find('div', class_='prod_main_info'):
# 상품 모델명, 가격, 이미지
name = v.select_one('p.prod_name > a').text.strip()
price = v.select_one('p.price_sect > a').text.strip()
img_link = v.select_one('div.thumb_image > a > img').get('data-original')
if img_link == None:
img_link = v.select_one('div.thumb_image > a > img').get('src')
print(name, price, img_link)
print()
# 브라우저 종료
driver.close()
|