Web 크롤링/Python Crawling
파이썬 selenium 활용 네이버 뉴스 스탠드 크롤링
Link2Me
2021. 6. 28. 13:33
728x90
네이버 뉴스 스탠드 정보를 크롤링하는 예제이다.

소스코드 구현
|
# 네이버 뉴스 스탠드 크롤링
# BeautifulSoup은 HTML 과 XML 파일로부터 데이터를 수집하는 라이브러리
# pip install selenium
# pip install chromedriver-autoinstaller
# pip install bs4
from selenium import webdriver
import chromedriver_autoinstaller
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
options = Options()
options.add_argument('headless'); # headless는 화면이나 페이지 이동을 표시하지 않고 동작하는 모드
# webdirver 설정(Chrome, Firefox 등)
chromedriver_autoinstaller.install()
driver = webdriver.Chrome(options=options) # 브라우저 창 안보이기
# driver = webdriver.Chrome() # 브라우저 창 보이기
# 크롬 브라우저 내부 대기 (암묵적 대기)
driver.implicitly_wait(5)
# 브라우저 사이즈
driver.set_window_size(1920,1280)
# 페이지 이동(열고 싶은 URL)
baseURL = 'https://www.naver.com/'
driver.get(baseURL)
soup = BeautifulSoup(driver.page_source, 'html.parser')
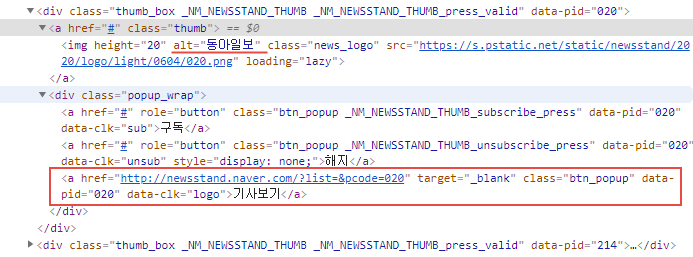
news_stand = soup.select('div.thumb_area > div')
print('-' * 25, end=' ')
print('네이버 뉴스 스탠드',end=' ')
print('-' * 25)
for v in news_stand:
title = v.select_one('a.thumb > img').get('alt')
news_url_all = v.select('div.popup_wrap > a')
for x in news_url_all:
if x.text.strip() == '기사보기':
news_url = x.get('href')
print(title, ', ', news_url)
print('-' * 70)
|
728x90