# pip install selenium
# pip install chromedriver-autoinstaller
# pip install bs4
# pip install xlsxwriter
from selenium import webdriver
import chromedriver_autoinstaller
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
import time
import xlsxwriter # 엑셀 처리 임포트
from io import BytesIO # 이미지 바이트 처리
import requests
class CRAWL:
def __init__(self):
self.options = Options()
self.options.add_argument('headless'); # headless는 화면이나 페이지 이동을 표시하지 않고 동작하는 모드
chromedriver_autoinstaller.install()
self.driver = webdriver.Chrome(options=self.options) # 브라우저 창 안보이기
# self.driver = webdriver.Chrome() # 브라우저 창 보이기
# Excel 처리 선언
self.savePath = "./"
self.workbook = xlsxwriter.Workbook(self.savePath + 'crawling_result.xlsx')
# 워크 시트
self.worksheet = self.workbook.add_worksheet()
self.totalPage = 1 # 전체 페이지수
def getBaseURL(self,url):
self.driver.implicitly_wait(5) # 크롬 브라우저 내부 대기 (암묵적 대기)
self.driver.set_window_size(1920,1280) # 브라우저 사이즈
self.driver.get(url)
# 제조사별 검색
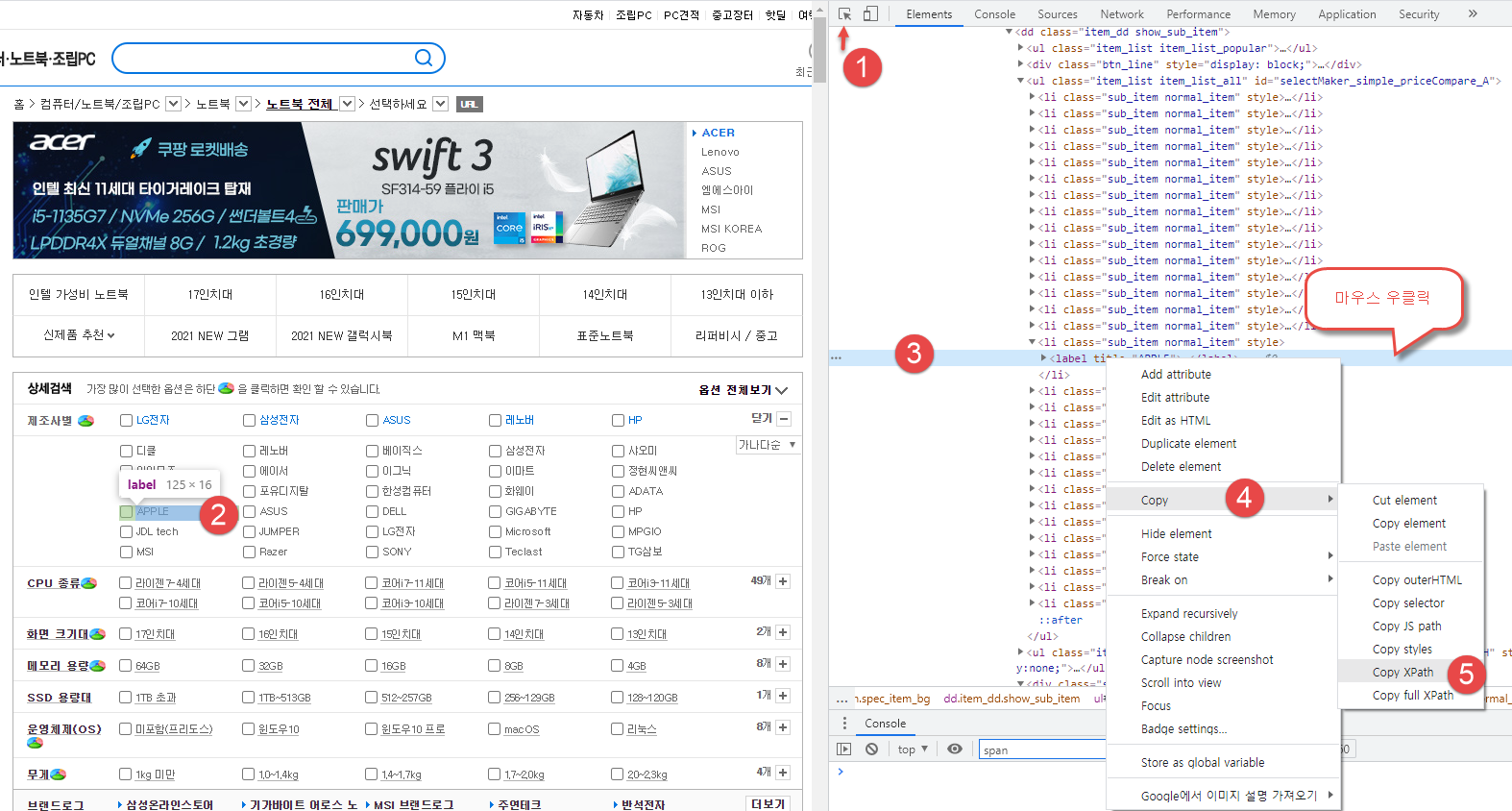
mft_xpath = '//*[@id="dlMaker_simple"]/dd/div[2]/button[1]'
WebDriverWait(self.driver,3).until(EC.presence_of_element_located((By.XPATH,mft_xpath))).click()
# 원하는 모델 카테고리 클릭
model_xpath = '//*[@id="selectMaker_simple_priceCompare_A"]/li[16]/label'
WebDriverWait(self.driver,3).until(EC.presence_of_element_located((By.XPATH,model_xpath))).click()
time.sleep(3) # 검색 결과가 랜더링될 때까지 잠시 대기
def getTotalPage(self,url):
self.getBaseURL(url)
soup = BeautifulSoup(self.driver.page_source, 'html.parser')
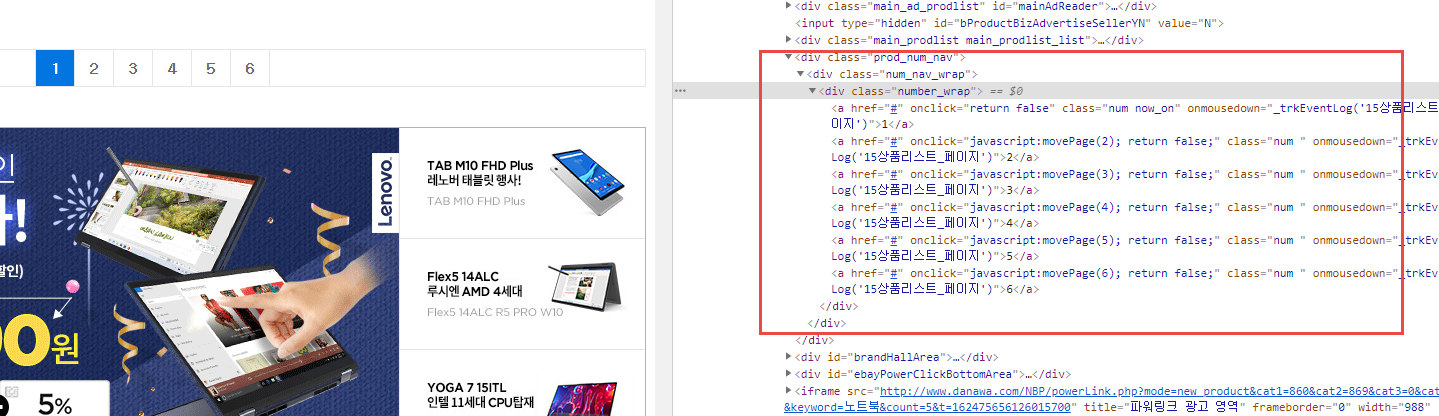
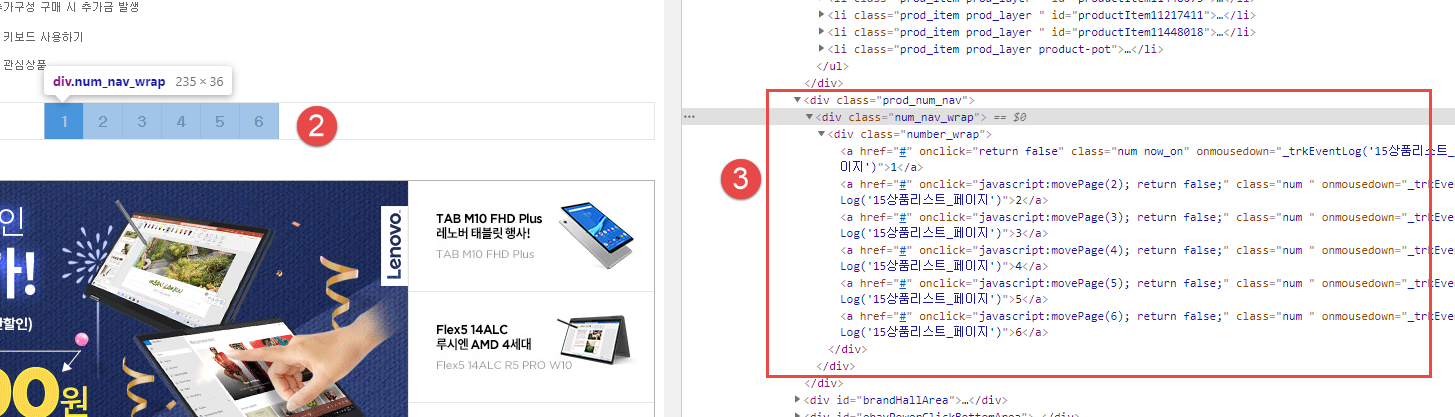
page_list = soup.select('div.number_wrap > a.num')
for v in page_list:
cur_Page = v.text.strip()
self.totalPage = cur_Page
del soup
def crawling(self,url):
self.getTotalPage(url)
totalPage = int(self.totalPage) # 크롤링할 전체 페이지수
print('total Pages : ',totalPage)
curPage = 1 # 현재 페이지
excel_row = 1 # 엑셀 행 수
self.worksheet.set_column('A:A', 40) # A 열의 너비를 40으로 설정
self.worksheet.set_row(0,18) # A열의 높이를 18로 설정
self.worksheet.set_column('B:B', 12) # B 열의 너비를 12로 설정
self.worksheet.set_column('C:C', 60) # C 열의 너비를 60으로 설정
self.worksheet.write(0, 0, '제품 모델명')
self.worksheet.write(0, 1, '가격')
self.worksheet.write(0, 2, '이미지 URL')
while curPage <= totalPage:
#bs4 초기화
soup = BeautifulSoup(self.driver.page_source, 'html.parser')
# 상품 리스트 선택
goods_list = soup.select('li.prod_item.prod_layer')
# 페이지 번호 출력
print('----- Current Page : {}'.format(curPage), '------')
for v in goods_list:
# 상품모델명, 가격, 이미지
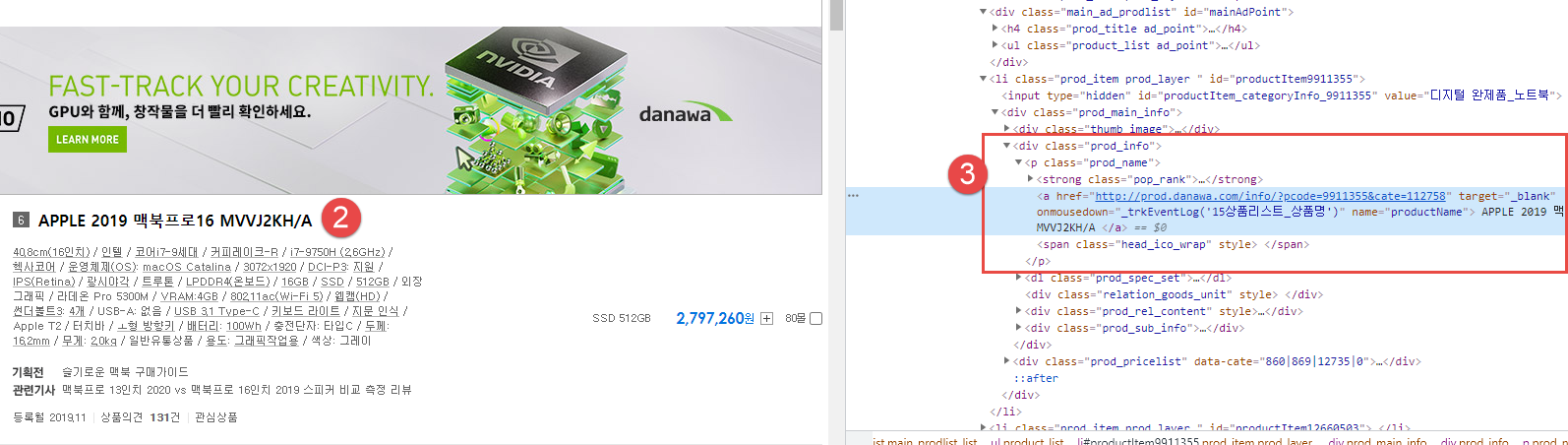
name = v.select_one('p.prod_name > a').text.strip()
if not 'APPLE' in name: # 개발자 모드 및 브라우저 상에서는 보이지 않는 데이터 대상에서 제외
continue
price = v.select_one('p.price_sect > a').text.strip()
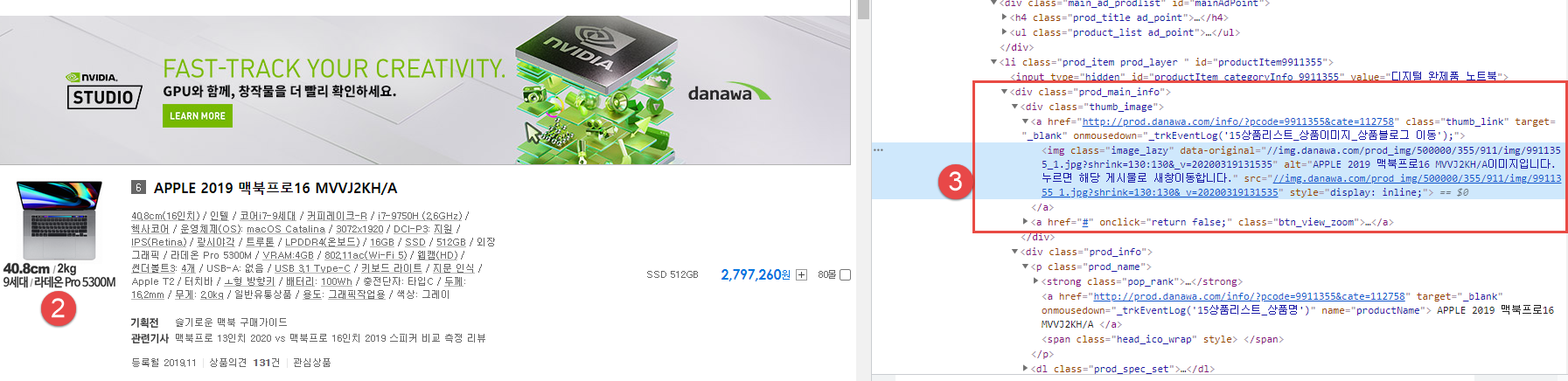
img_link = v.select_one('div.thumb_image > a > img').get('data-original')
if img_link == None:
img_link = v.select_one('div.thumb_image > a > img').get('src')
imgLink = img_link.split("?")[0].split("//")[1]
img_url = 'https://{}'.format(imgLink)
# 이미지 요청 후 바이트 반환
res = requests.get(img_url) # 이미지 가져옴
img_data = BytesIO(res.content) # 이미지 파일 처리
image_size = len(img_data.getvalue()) # 이미지 사이즈
# 엑셀 저장(텍스트)
self.worksheet.write(excel_row, 0, name)
self.worksheet.write(excel_row, 1, price)
# 엑셀 저장(이미지)
if image_size > 0: # 이미지가 있으면
# 이미지 저장이 안되어서 그냥 텍스트로 이미지 URL 저장 처리
# worksheet.insert_image(excel_row, 2, img_url, {'image_data' : img_data})
self.worksheet.write(excel_row,2,img_url) # image url 텍스트 저장
excel_row += 1 # 엑셀 행 증가
# 페이지별 스크린 샷 저장
self.driver.save_screenshot(self.savePath + 'target_page{}.png'.format(curPage))
curPage += 1 # 페이지 수 증가
if curPage > totalPage:
print('Crawling succeed!')
break
# 페이지 이동 클릭
cur_css = 'div.number_wrap > a:nth-child({})'.format(curPage)
WebDriverWait(self.driver,3).until(EC.presence_of_element_located((By.CSS_SELECTOR,cur_css))).click()
del soup # BeautifulSoup 인스턴스 삭제
time.sleep(3) # 3초간 대기
def closing(self):
self.driver.close() # 브라우저 종료
# 엑셀 파일 닫기
self.workbook.close() # 저장
if __name__ == "__main__":
baseURL = 'http://prod.danawa.com/list/?cate=112758&15main_11_02'
crawl = CRAWL()
crawl.crawling(baseURL)
crawl.closing()