728x90
Python 에서 SQLite3 데이터베이스 연동을 처리하는 예제이다.
SQLite DB 테이블 생성시 unique 인덱스 설정과 DB 데이터 추가시 중복 저장될 경우 처리를 고려하여 테스트했다.
|
import datetime
import sqlite3
def query_sqlite(input_query):
import sqlite3
# DB 생성 및 Auto Commit
dbconn = sqlite3.connect('database.db', isolation_level=None)
cur = dbconn.cursor() # 커서 획득
cur.execute(input_query) # SQL 쿼리 실행
# 데이타 Fetch
rows = cur.fetchall()
for row in rows:
print(row)
dbconn.close() # Connection 닫기
# 날짜 삽입 과정
now = datetime.datetime.now()
print('now :', now)
nowDatetime = now.strftime('%Y-%m-%d %H:%M:%S')
print('nowDatetime :', nowDatetime)
print('sqlite3.version :', sqlite3.version)
print('sqlite.sqlite_version :', sqlite3.sqlite_version)
# DB 생성 및 Auto Commit
conn = sqlite3.connect('database.db', isolation_level=None)
# 커서 획득
c = conn.cursor()
# 테이블 생성(Data Type : TEXT, INTEGER, REAL, BLOB, NUMERIC)
# 컬럼에 UNIQUE 제약 조건을 설정하면 대상의 컬럼에 중복 된 값이 저장될 수 없다.
sql = 'CREATE TABLE IF NOT EXISTS users(id INTEGER PRIMARY KEY, username text, email text not null unique , phone text, regdate text)'
c.execute(sql)
# 여러 컬럼의 조합에 UNIQUE 제약 조건 설정
# CREATE TABLE 테이블명 (컬럼명1, 컬럼명2, ... , UNIQUE (컬럼명1, 컬럼명2, ...));
# create table users (id INTEGER PRIMARY KEY, username text, email text unique , phone text, regdate text, unique (id, email));
# 데이터 삽입
varlist = [2, '이방원', 'bwlee@naver.com', '010-0001-0002']
print(varlist)
varlist.append(nowDatetime)
print(varlist)
# 동일 데이터가 들어오면 저장하지 말라는 옵션 추가
# 일반 Query : INSERT INTO
var_string = ', '.join('?' * len(varlist))
query_string = 'INSERT OR IGNORE INTO users VALUES (%s);' % var_string
print(query_string)
c.execute(query_string, varlist)
# SQL 쿼리 실행
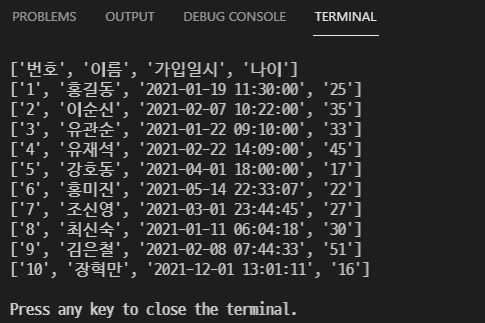
query_sqlite('select * from users')
# 다량의 데이터 추가
userList = (
(3,'박창근', 'park@naver.com', '010-0001-0003',nowDatetime),
(4,'이원빈', 'wblee@naver.com', '010-0001-0004',nowDatetime),
(5,'장길산', 'gsjang@naver.com', '010-0001-0005',nowDatetime),
)
sql = "INSERT OR IGNORE INTO users(id, username, email, phone, regdate) VALUES(?,?,?,?,?)"
c.executemany(sql,userList)
conn.close()
# sqlite3 에서는 ? mariaDB 에서는 %s
# SQL 쿼리 실행
query_sqlite('select * from users')
|
'파이썬 > Python 기초' 카테고리의 다른 글
| [파이썬기초] SQLite 사용한 텍스트 기반 간단 쇼핑몰 예제 (0) | 2021.06.27 |
|---|---|
| [Python] MariaDB 연결 (0) | 2021.05.20 |
| csv 파일 다루기 (0) | 2021.05.11 |
| 람다 표현식으로 함수 만들기 (0) | 2021.05.10 |
| [파이썬기초] list comprehension (0) | 2021.05.04 |

Link2Me