
초보수준으로 약간 배우고 오랫만에 Python 을 사용하니까 생각나는게 하나도 없어서 테스트하면서 적어둔다.
가장 먼저 해야 할일은 크롬 브라우저에서 개발자 모드(F12) 상태에서 원하는 정보를 클릭하는 것이다.
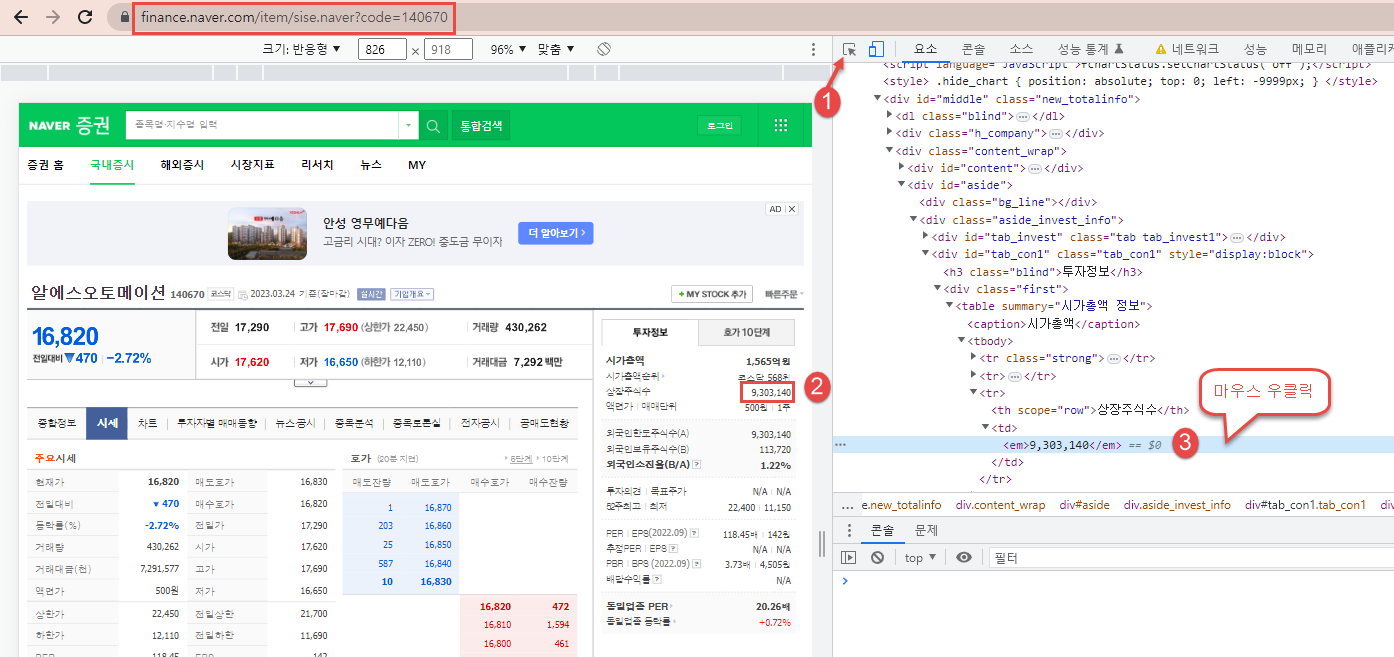
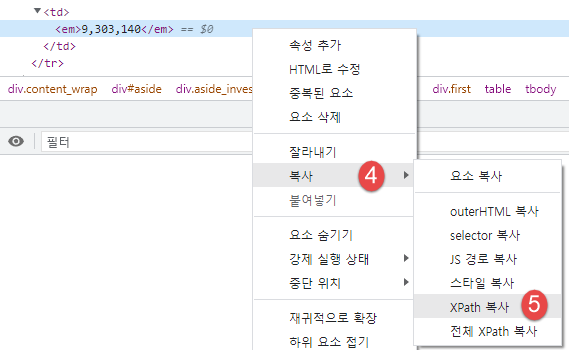
//*[@id="tab_con1"]/div[1]/table/tbody/tr[3]/td/em
XPath 복사 결과는 위와 같다.
selector 복사를 하면....
#tab_con1 > div.first > table > tbody > tr:nth-child(3) > td > em
와 같은 결과를 반환해준다.
이 결과를 그대로 사용하면 원하는 결과가 나오지 않기 때문에 태그 구조를 파악하면서 결과를 얻어내야 한다.
원하는 정보를 가져오기 위한 준비를 마치고 Code 상에서 확인하는 작업을 한다.
텍스트 형태의 데이터에서 원하는 HTML 태크를 추출하는 쉽게 도와주는 라이브러리가 BeautifulSoup 이다.
먼저 table 태그를 출력해보고 원하는 자료가 몇번째 tr 에 있는지 확인하고 원하는 값을 추출한다.
데이터의 형태가 추출하기 쉽게 되어 있지 않는 경우도 있으니 split('\n') 를 사용하여 배열 구조를 파악해서
원하는 결과를 출력해야 하는 시가총액 정보도 있다.
|
import requests
# BeautifulSoup은 HTML 과 XML 파일로부터 데이터를 수집하는 라이브러리
from bs4 import BeautifulSoup
# BeautifulSoup 에서는 Xpath 사용 불가능
def financialData(code):
url = 'https://finance.naver.com/item/sise.naver?code='+ str(code)
res = requests.get(url)
if res.status_code == 200:
html = res.text
# HTML 페이지 파싱 BeautifulSoup(HTML데이터, 파싱방법)
soup = BeautifulSoup(html, 'html.parser')
# parents : 선택한 요소 위로 올라가면서 탐색하는 도구
# next_siblings : 동일 레벨에 있는 태그들을 가져온다.
# //*[@id="tab_con1"]/div[1]/table/tbody/tr[3]
# find() : 가장 먼저 검색되는 태그 반환
body = soup.select_one("#tab_con1 > div.first > table")
print(body.prettify()) # 보기 좋게 출력
# 시가총액 가져오기
market_sum_init= soup.select('#tab_con1 > div.first > table > tr')[0].find('td').text.split('\n')
print(market_sum_init)
market_sum = market_sum_init[4].strip() + market_sum_init[7].strip()
print(market_sum)
# 상장 주식수 가져오기
stock_num = soup.select('#tab_con1 > div.first > table > tr')[2].find('td').text
print(stock_num)
else:
print(res.status_code)
if __name__ == '__main__':
financialData(140670)
|
거래량 가져오기
find는 가장 가까운 태그 하나를 찾는다.
find(태그,Class명)
find(태그, id='address')
개발자모드에서 select 값을 찾아 보니 아래와 같다.
이걸 활용하여 soup.select('#chart_area > div.rate_info > table > tr')[0] 를 한 다음에 print 출력으로 구조를 파악한다.
td 태그 중에서 3번째 태크가 원하는 값이 있다는 걸 확인할 수 있다.
.select('td')[2].find('span','blind').text 으로 최종 원하는 결과를 얻을 수 있다.
|
# #chart_area > div.rate_info > table > tbody > tr:nth-child(1) > td:nth-child(3) > em
stock_rateinfo = soup.select('#chart_area > div.rate_info > table > tr')[0].select('td')[2].find('span','blind').text
print(stock_rateinfo)
|
'Web 크롤링 > Python Crawling' 카테고리의 다른 글
| 파이썬 selenium 드라이버 설치 없이 사용하자. (0) | 2024.03.24 |
|---|---|
| 네이버 증권 정보 크롤링 예제 2 - 일별 시세 정보 가져오기 (0) | 2023.03.31 |
| 파이썬 selenium 활용 네이버 뉴스 스탠드 크롤링 (0) | 2021.06.28 |
| 파이썬 selenium 활용 다나와 제품 검색 모든 페이지 크롤링 (0) | 2021.06.28 |
| 파이썬 selenium 으로 다나와 제품 검색 페이지 전환 엑셀 저장 (0) | 2021.06.27 |

Link2Me