
판다스를 이용하면 대용량의 데이터도 쉽게 읽어서 분석할 수 있다.
https://www.data.go.kr/ 에서 샘플 데이터 가져오기

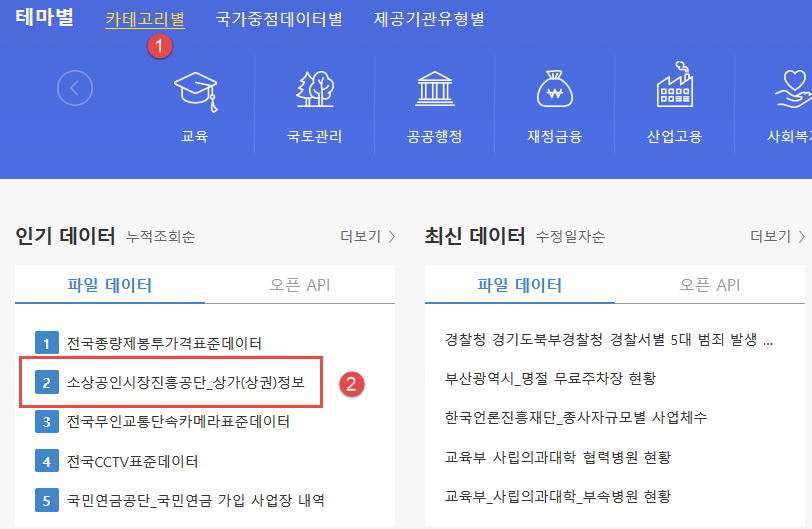

다운로드 받은 파일이 압축파일이며, 내용을 보면 아래와 같이 csv 파일로 되어 있다.
서울 파일을 영문이름으로 변경했다.

이제, 파이참(PyCharm)에서 코드를 실행해 본다.
https://www.w3schools.com/python/pandas/default.asp 에 기본적인 코드 사용법이 잘 나와있다.

|
import pandas as pd
# data = pd.read_csv('soho_seoul.csv', header=None) # KeyError: '상권업종대분류명'
df = pd.read_csv('soho_seoul.csv') # KeyError: '상권업종대분류명'
## Fastest would be using length of index
print("전체 행 : ", len(df.index))
## If you want the column and row count then
row_count, column_count = df.shape
print("총 행(row) 수 : ", row_count)
print("총 칼럼(열) 수 : ", column_count)
# 데이터 셋 df의 종합적인 정보는 df.info( ) 함수를 통해 확인 가능
# Dtype의 int64는 정수, object는 문자열, float64는 실수를 의미
print(df.info())
# 데이터 프레임에서 결측치를 True, 값이 있으면 False를 반환
print(df.isnull())
# 각 column들이 몇개의 null값을 가졌는지 확인
is_null = df.isnull().sum()
print(is_null)
|
jupyter notebook 에서 df.info() 를 한 결과 화면이다.

열의 칼럼이 39개나 되어서 출력 결과가 보기 좋지 않아 칼럼 일부만 발췌해서 출력하는 걸 테스트했다.
|
# 위에서부터 지정된 개수만큼 출력하기
df_head = df.head(10) # 개수를 지정하지 않으면 기본 5개 출력
print(df_head)
# 3 ~ 6번째 데이터 출력, 칼럼(열)은 10번째 열까지 출력
print(df.iloc[2:7,:10])
# 열 여러개 선택하기
new_df = df.head(20)[['상호명','상권업종대분류명','상권업종중분류명','상권업종소분류명','표준산업분류명','시군구명','행정동명','건물명']]
print(new_df)
# 맨 하단 10개 데이터를 칼럼(열) 10개만 출력
print(df.tail(10).iloc[:,:10])
print(df.tail(10)[['상가업소번호','상호명','상권업종대분류명','상권업종중분류명','상권업종소분류명','표준산업분류명','시군구명','행정동명','건물명']])
|
특정 칼럼 중복 제거 및 DB에 데이터 저장
|
# 특정 칼럼 중복 제거
item = df['상권업종대분류명'].drop_duplicates()
print(item)
# LIST로 변환
item_list = item.values.tolist()
print(item_list)
# 가나다순 정렬
varlist = sorted(item_list)
print(varlist)
# LIST to DB Insert
|
판다스에서 읽은 데이터를 mariaDB에 저장 테스트 목적으로 샘플 테이블을 생성했다.
다중 카테고리로 사용하는 테이블이다.
|
CREATE TABLE cate (
`id` int(11) NOT NULL,
`parent_id` int(11) NOT NULL DEFAULT 0,
`depth` int(3) NOT NULL DEFAULT 1,
`name` varchar(50) NOT NULL,
`text` varchar(50) DEFAULT NULL
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
ALTER TABLE cate
ADD PRIMARY KEY (`id`);
ALTER TABLE cate
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT;
COMMIT;
|
데이터 무결성(중복 저장 방지)을 위해서 다중칼럼 UNIQUE 인덱스를 추가했다.
parent_id, depth, name 칼럼이 마치 1개의 칼럼처럼 동작하여 동일한 자료가 업로드되면 추가되지 않는다.
보통 userID 가 중복되지 않도록 1개의 칼럼에 UNIQUE 인덱스를 설정하는데, 데이터가 중복 저장되지 않도록 하기 위한 모든 칼럼에 다중 UNIQUE INDEX를 설정하면 중복 저장을 방지할 수 있다.
|
ALTER TABLE cate
ADD UNIQUE KEY parentid_name (parent_id,depth,name);
|
DB에 데이터 Insert 과정의 소스 코드
csv 파일의 데이터를 읽어서 원하는 칼럼의 자료를 선택하고 중복된 값을 제거하고 DB에 카테고리화를 위한 데이터 저장 목적으로 코드를 연습해 본 것이다.
|
# pip install PyMySQL # mysql 연동시
# pip install mariadb
# pip install numpy scipy matplotlib ipython scikit-learn pandas pillow imageio
import pandas as pd
import mariadb
import sys
# Connect to MariaDB Platform
try:
mydb = mariadb.connect(
user="root",
password="autoset",
host="localhost",
port=3306,
database="python_sample"
)
except mariadb.Error as e:
print(f"Error connecting to MariaDB Platform: {e}")
sys.exit(1)
# Get Cursor
dbconn = mydb.cursor()
# data = pd.read_csv('soho_seoul.csv', header=None) # KeyError: '상권업종대분류명'
df = pd.read_csv('soho_seoul.csv') # KeyError: '상권업종대분류명'
## Fastest would be using length of index
print("전체 행 : ", len(df.index))
## If you want the column and row count then
row_count, column_count = df.shape
print("총 행(row) 수 : ", row_count)
print("총 칼럼(열) 수 : ", column_count)
# 특정 칼럼 중복 제거
item = df['상권업종대분류명'].drop_duplicates()
print(item)
# LIST로 변환
item_list = item.values.tolist()
print(item_list)
# 가나다순 정렬
varlist = sorted(item_list)
print(varlist)
# 배열 사이즈 구하기
print(len(varlist))
# 배열 사이즈만큼 동일한 값 초기화, 두가지 방법 모두 가능
parent_id = [0 for i in range(len(varlist))]
depth = [1] * len(varlist)
# Series 생성 및 DataFrame 전환 <== mariaDB 입력 데이터 생성 목적
df_parentid = pd.Series(parent_id)
df_depth = pd.Series(depth)
df_name = pd.Series(varlist)
df_all = pd.concat([df_parentid, df_depth, df_name, df_name], axis=1)
print(df_all)
# DataFrame to List
db_itemlist = df_all.values.tolist()
print(db_itemlist)
# LIST to mariaDB Insert
sql = "INSERT INTO cate(parent_id,depth,name,text) VALUES(%s,%s,%s,%s)"
dbconn.executemany(sql,db_itemlist)
|
DB에 잘 저장되었는지 여부를 확인해 보자.
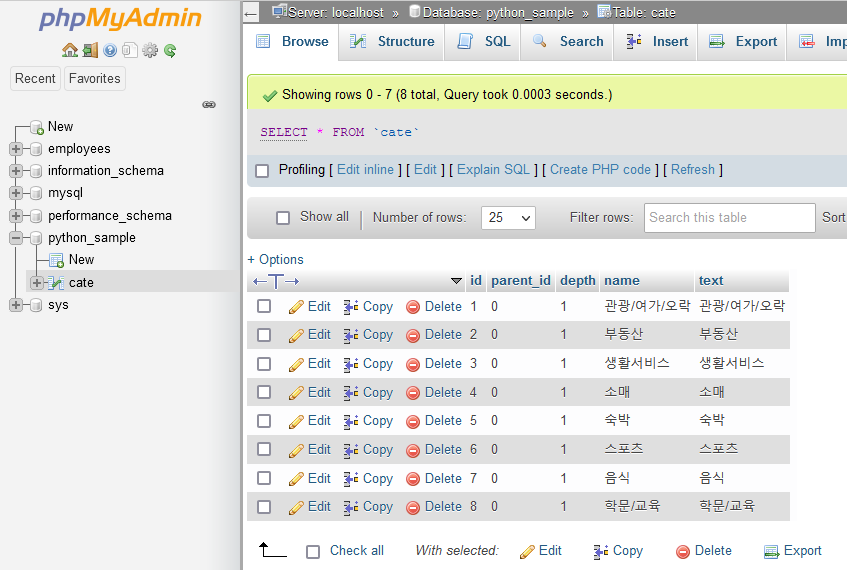
파일을 다시 한번 더 실행하면 아래와 같은 에러 메시지를 출력한다.

위와 같은 메시지가 출력되는 걸 방지하고 싶다면, INSERT IGNORE INTO 로 변경하면 된다.
중복하려는 자료가 있다면 기존 자료를 유지하고, 새로운 자료는 무시하라는 명령어이다.
|
# LIST to mariaDB Insert
sql = "INSERT IGNORE INTO cate(parent_id,depth,name,text) VALUES(%s,%s,%s,%s)"
dbconn.executemany(sql,db_itemlist)
dbconn.close()
|
'파이썬 > 데이터 분석' 카테고리의 다른 글
| MariaDB to Python Pandas DataFrame (0) | 2022.01.21 |
|---|---|
| Python Pandas 기초 학습 (0) | 2022.01.18 |
| Pycharm과 Jupyter Notebook 연결하기 (0) | 2022.01.12 |

Link2Me