
beautifulSoup 의 기본적인 사항을 알아보자.
|
# bs4 초기화
soup = BeautifulSoup(html, 'html.parser')
# 타입 확인
print('soup', type(soup))
# 코드 정리
print('prettify', soup.prettify())
# h1 태그 접근
h1 = soup.html.body.h1
print('h1', h1)
# p 태그 접근
p1 = soup.html.body.p
print('p1', p1)
# 다음 태그
p2 = p1.next_sibling.next_sibling
print('p2', p2)
|
|
link1 = soup.find_all("a", class_='sister') # {} 다중 조건
print(link1)
# 다중 조건
link1 = soup.find("a", {"class": "sister", "data-io": "link1"})
# CSS 선택자
# 태그 + 클래스 + 자식 선택자
link1 = soup.select_one("p.title > b")
# 태그 + id 선택자
link1 = soup.select_one("a#link1")
# 태그 + 속성 선택자
link1 = soup.select_one("a[data-io='link1']")
|
|
soup.find('a') # <a href="www.google.com">구글</a>
soup.find('a').get('href') # www.google.com
soup.find('a').get_text() # 구글
|
필요 자료는 구글 크롬브라우저 개발자 도구를 이용하면 html 구조를 파악할 수 있다.
예제로 https://kin.naver.com/search/list.nhn?query=%ED%8C%8C%EC%9D%B4%EC%8D%AC 사이트를 선택했다.

ul 태그 하위 요소로 li 태그가 10개 인것을 확인할 수 있다.

DOM 트리 구조를 보면 ul > li > dl > dt > a 태그 순으로 되어 있다.
원하는 정보를 추출하기 위한 정보 파악은 된 거 같다.

파이썬 코드 및 pip 인스톨 사항
파이썬에서 기본적으로 내장된 함수가 아니기 때문에 pip 인스톨을 해준 후에 해당 라이브러리를 import 해준다.
|
# 네이버 검색결과 크롤러 만들기
# BeautifulSoup은 HTML 과 XML 파일로부터 데이터를 수집하는 라이브러리
# pip install bs4
# pip install requests
import requests
from bs4 import BeautifulSoup
#import ssl
url = 'https://kin.naver.com/search/list.nhn?query=%ED%8C%8C%EC%9D%B4%EC%8D%AC'
response = requests.get(url)
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, 'html.parser')
ul = soup.select_one('ul.basic1')
titles = ul.select('li > dl > dt > a')
for title in titles:
print(title.get('href'))
else :
print(response.status_code)
|
find(복수는 find_all)와 select(한 개 찾을때에는 select_one) 를 이용한 방법으로 나눌 수 있다.
링크는 <a href = '주소'> 누르면 다운</a> 이런 형태로 되어있다.
soup.select('a')[0]['href'] 이런 식으로 한정한 이후 [속성명] 을 넣어주면 속성 값을 가져올 수 있다.
# 링크 주소를 가져올때(첫 번째 꺼 하나만)
select('a')[0]['href']
SELECT 설명
select(), select_one() 설명
| 태그이름 | 태그이름으로 찾음 |
| .클래스이름 | 클래스이름으로 찾음 |
| #아이디이름 | 아이디이름으로 찾음 (아이디는 연속X) |
| 상위태그이름 > 자식태그 > 자식태그 | 부모 자식간의 태그 조회' >' 로 구분 |
| 상위태그이름 자손태그 | 부모 자손간의 태그 조회 #띄어쓰기(공백) 로 구분 #자식을 건너 띈다. |
| [속성] | 태그 안의 속성을 찾음 |
| 태그이름.클래스이름 | 해당태그의 클래스이름을 찾음 |
| #아이디이름 > 태그이름.클래스이름 | 아이이디 이름으로 찾고 자식태그와 클래스이름으로 찾음 |
실행 결과
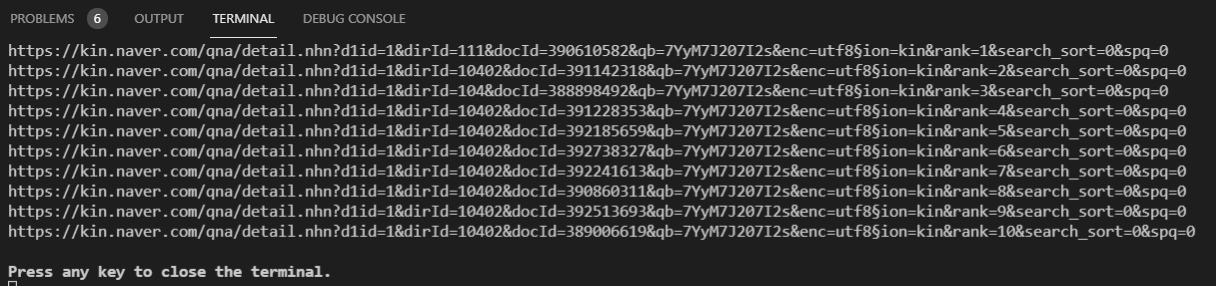
페이지를 파싱처리 하다보면 iframe을 사용한 코드를 만날 수 있다.
<iframe src="삽입할페이지주소" width="너비" height="높이"></iframe>
아래 코드는 네이버 증권 정보를 파싱처리하는 코드 예시다.
|
import requests
from fake_useragent import UserAgent
# BeautifulSoup은 HTML 과 XML 파일로부터 데이터를 수집하는 라이브러리
from bs4 import BeautifulSoup
import pymysql
import re
import os, sys
from io import StringIO
# PHP로부터 전달받은 코드변수
code = sys.argv[1]
def coinInfoData(code):
url = f'https://finance.naver.com/item/coinfo.naver?code={code}'
ua = UserAgent()
headers = {'User-agent': ua.ie}
res = requests.get(url, headers=headers)
if res.status_code == 200:
html = res.text
# HTML 페이지 파싱 BeautifulSoup(HTML데이터, 파싱방법)
soup = BeautifulSoup(html, 'html.parser')
# 보유지분이 포함된 페이지 iframe
frame = soup.find('iframe', id="coinfo_cp")
# iframe의 url 추출
frameaddr = frame['src']
frame_res = requests.get(frameaddr, headers=headers)
if frame_res.status_code == 200:
# HTML 페이지 파싱
frame_soup = BeautifulSoup(frame_res.text, 'html.parser')
# #cTB13 > tbody
coinfo = frame_soup.find_all('td',{'class':'noline-right num'})
# print(coinfo)
sum = 0
for val in coinfo:
info = val.text.strip()
if not info == '':
info = float(info)
sum = sum + info
# print(sum)
conn = pymysql.connect(host="localhost", user="", password="", db="", charset="utf8")
curs = conn.cursor()
sql = "update stocks SET LSholdings=%s where code=%s"
val = (sum,str(code))
curs.execute(sql, val)
conn.commit()
conn.close()
print('Finished')
else:
print(frame_res.status_code)
else:
print(res.status_code)
if __name__ == '__main__':
coinInfoData(code)
|
'파이썬 > Crawling 기초' 카테고리의 다른 글
| [크롤링기초] 행정안전부 RSS 정보 크롤링 예제 (0) | 2021.06.22 |
|---|---|
| [크롤링기초] 사이트 정보 확인 (0) | 2021.06.22 |
| [크롤링 기초] lxml 활용한 네이버 지식인 정보 가져오기 (0) | 2021.06.22 |
| 네이버 헤드라인 뉴스 가져오기 실패 그리고 성공 (0) | 2021.06.22 |
| [파이썬] 크롤링 기초 예제 네이버 이미지 다운로드 (0) | 2021.06.17 |

Link2Me