정규표현식은 1970년대에 등장한 오래된 기술이다.
유닉스나 리눅스 시스템을 다루는 사람이라면 더더욱 잘 알아야 한다.
정규표현식을 처음에 접하면 너무 생소해서 어렵게만 느껴진다.
정규표현식을 제대로 다룰 줄 모르다보니 구글링 검색만 많이 하게 되는데 조금이라도 이해하고자 적어본다.
정규표현식은 텍스트에서 원하는 패턴을 찾는 도구다.
? : 0 또는 하나 {0,1} 와 같다.
+ : 1개 이상 {1,} 와 같다.
* : 0 개 이상 {0,} 과 같다.
[] : []안에 있는 문자열 중 한문자. 정규표현식에서 대괄호는 일반 문자가 아닌 메타문자로 인식한다.
{} : {} 바로 앞에 있는 문자열(또는 문자)의 개수
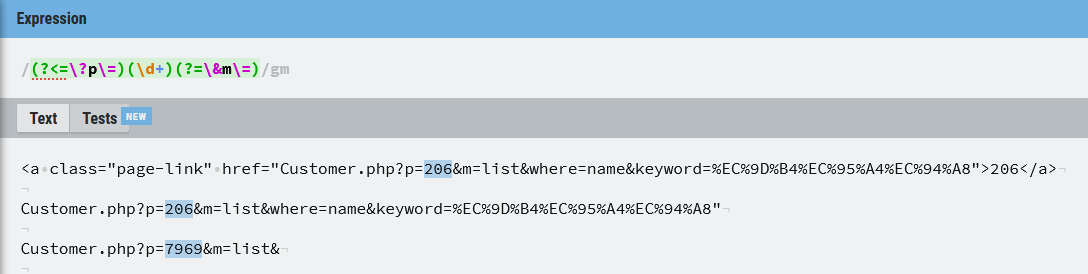
() : ()안에 있는 문자들의 그룹화. ( : 참조그룹 시작, ) : 참조그룹 끝.
| : OR 연산자 기능
w : 영문자, 숫자, _, 기타 스크립트 문자
W : 영문자, 숫자, _, 기타 스크립트 문자를 제외한 문자
s : 공백
S : 공백을 제외한 모든 문자
D : 숫자가 아닌 모든 문자
d : 숫자
i : 대소문자 무시
정규식으로 한글의 범위는 \xa1-\xfe 로 표현
^ : 문자열의 시작
$ : 문자열의 마지막. 행의 끝.
. : 문자열중 임의의 한문자(개행문자 제외) |
a{2}b : aab 를 가진 문자열을 사용할 수 있다. 즉 (2) 는 {} 앞에 있는 문자 a 의 개수가 2개인 것을 의미
() : 찾는 패턴의 전체 또는 일부분을 괄호를 사용해서 그룹으로 묶으면 그 내용이 임시로 메모리에 저장된다.
사용할 수 있는 문자열을 지정하는 정규 표현식의 문자는 [] 이다.
[-.]? : 하이픈 또는 점이 0번 또는 1번 나온다는 의미다.
특정 문자열을 사용할 수 없도록 지정하고 싶다면, 지정하는 대괄호 [] 사이에 삿갓(^) 표시를 입력하면 된다.
[^123] 과 같이 사용하면 1,2,3 숫자는 문자열로 사용할 수 없다.
[] 안의 두 문자 사이에 하이픈(-)을 사용하게 되면 두 문자 사이의 범위(From - To)를 의미한다.
[0-9] : 0 ~ 9 까지의 숫자를 찾는다.
[5-9] : 5 ~ 9 사이의 숫자를 찾는다.
\d : 0 ~9 까지의 숫자중 하나
\D : 숫자가 아닌 문자를 모두 찾는다.
[^0-9] : 숫자가 아닌 문자를 모두 찾는다.
바로 앞 문자열의 반복을 의미하는 *,+,? 문자
.* : 임의의 문자를 0개 이상 찾아라.
정규 표현식의 Dot(.) 메타 문자는 줄바꿈 문자인 \n를 제외한 모든 문자와 매치됨을 의미한다.
[^\n]* 과 같이 사용하면 개행문자(\n)가 아닌 문자를 0개 이상 찾아라.
정규 표현식에서 특수문자를 사용하기 위한 역슬래시(\)
실제 사용해야 할 특수문자가 있을 때는 그 문자 앞에 역슬래시(\)로 해당 문자열을 이스케이프해야 한다.
^[_0-9a-zA-Z-] : ^ 는 문자열의 시작을 알리는 것이다.
처음 문자열 시작을 0 에서 9 까지의 숫자나 소문자 a 에서 소문자 z, 대문자 A 에서 대문자 Z 까지 사용
/^[a-z]+$/i : 대소문자 구분없이 알파벳으로 이루어진 문자열
\ : 이스케이프 문자. 여러 메타 문자들을 이스케이프하여 그대로 사용할 수 있게 한다.
*, ?, +, [, { ,(, ), }, ], ^, $, |, \, . 등
$idx = "192.168.1.1가나다aacc";
$idx = preg_replace("/[^0-9\.]/", "", $idx); // 숫자와 컴마 이외 제거
$str = "https://www.abc.com/abc.php?mode=n&p=1&keyword='love'";
// $str 의 내용중 mode까지의 문자열 저장
$str = preg_replace('/(mode)(.*)/',"$1",$str);
echo $str.'<br/>';
$str = '<th scope="col">에러코드</th>';
$str = preg_replace("/<\/?(td|tr|tbody)[^>]*>/i", "", $str);
// [^>]* 는 > 가 아닌 문자를 0개 이상 찾아라.
echo $str.'<br/>';
preg_match($pattern, $str, $match);
$pattern : 정규식 패턴, $str : 추출할 문장, $match : 추출된 값을 배열에 저장
preg_match_all("패턴", "추출할 문장", "결과 배열");
preg_match - 첫번째 매치가 일어나면 실행을 중지한다. (즉, 최대 매치횟수는 1회)
preg_match_all - 전체 매치된 횟수를 반환하며, 오류시 FALSE를 반환한다.
<?php
$str = "부산광역시 연제구 (연산 1동) 158-77";
//preg_match("/\(\S+\)/",$str,$matches);
//preg_match("/\([^\s]+\)/",$str,$matches); // \S 는 [^\s] 와 같다.
preg_match("/\(.*\)/",$str,$matches); // 괄호 시작과 종료안에서 .* 임의의 문자를 0개 이상 찾는다.
echo $matches[0]."<br />";
echo str_replace(array('(',')'),"",$matches[0]).'<br />';
##########################################
// http://www.naver.com
// https? : http 또는 https
// /^(((http(s?))\:\/\/)?)([0-9a-zA-Z\-]+\.)+[a-zA-Z]{2,6}(\:[0-9]+)?(\/\S*)?$/
$mobileNO = "010-1234-7777";
$mobileNO = preg_replace("/\D/", "", $mobileNO); // 숫자가 아닌 모든 문자는 제거하라.
$mobileNO = preg_replace("/(^01[0|1|6|7|8|9]{1})([0-9]{3,4})([0-9]{4})$/", "\\1-\\2-\\3", $mobileNO);
echo $mobileNO.'<br />';
// [] : []안에 있는 문자열 중 한문자
// () : ()안에 있는 문자들의 그룹화
// {} : {} 바로 앞에 있는 문자열(또는 문자)의 개수
// ^01 : 시작을 01로 시작하고 0,1,6,7,8,9 중 1개의 글자를 그룹화하라.
// ([0-9]{3,4}) : 숫자 0~9 중 3개 또는 4개를 그룹화하라.
// ([0-9]{4}) : 숫자 0~9 중 4개를 그룹화하라.
이미지 다운로드시 상위 폴더로 이동하기 위한 ../ 정보가 포함되어 있는 걸 방지
$str ="../../image.png";
$str=preg_replace("/\.{2}\//","",$str);
echo $str.'<br/>';
$url ="http://www.naver.com/index.php";
preg_match("/^(https?:\/\/)?([^\/]+)/i",$url,$matches);
// ^ 시작이 http:// 또는 https:// 로 시작하는 문자열이 ? (0 또는 1개)
// ?는 바로 앞에 있는 괄호의 반복()을 의미한다.
// ? : 0개 또는 1개
// + : 1개 이상
// [^\/] : /가 아닐 때까지 +(1개 이상) 즉, /를 만날때까지의 값
echo '<pre>';print_r($matches);echo '</pre>';
공백이 2칸 이상일 때 1칸으로 변경
$str ="I'm a office worker.";
$str=preg_replace("/\s{2,}/"," ",$str); // 연속된 공백을 1개의 공백으로 변경
echo $str.'<br/>';
// \s{2,} : 공백이 2개 이상이면
$str ="주석이전 내용; // 주석 처리할 내용";
$str = preg_replace('/\/\/([^\n]+)/', "", $str); // (.*) 과 ([^\n]+) 는 같다.
// //부터 시작하여 개행문자까지 모두 공백으로 처리하라.
echo $str.'<br />';
$str ="<!--홍길동-->";
preg_match("/--([^--]+)/",$str,$matches);
// -- 부터 시작해서 --를 만날때까지의 값 추출
echo '<pre>';print_r($matches);echo '</pre>';
SQL 인젝션 공격 시도 방지
SQL Injection은 웹 어플리케이션에서 DB에 Query시 입력된 데이터의 유효성 검증을 하지 않아,
개발자가 의도하지 않는 동적 쿼리(Dynamic Query) 를 생성하여 DB정보를 열람하거나 조작할 수 있는 보안 취약점이다.
$userID = "admin";
$password = "password' OR 1='1";
$sql = "SELECT * FROM members WHERE userID='{$userID}' AND passwd='{$password}'";
echo $sql.'<br/>'; // 이걸 DB 에서 실행해보면 패스워드 무력화가 된다는 걸 알 수 있다.
$sql=preg_replace("/\-/","",$sql); // 주석 제거
$sql=preg_replace("/\s{1,}1\=(.*)+/","",$sql); // 공백이후 1=1이 있을 경우 제거
$sql=preg_replace("/\s{1,}(or|and|null|where|limit)/i"," ",$sql); // 공백이후 or, and 등이 있을 경우 제거
echo $sql.'<br/>';
여기서 한가지 더 테스트를 해봤다.
$userID = "admin";
$password = mysqli_real_escape_string($db,"password' OR 1='1 --");
$sql = "SELECT * FROM members WHERE userID='{$userID}' AND passwd='{$password}'";
echo $sql.'<br/>';
결과 :
SELECT * FROM members WHERE userID='admin' AND passwd='password\' OR 1=\'1 --'
' 앞에 역슬레쉬(\)를 붙여서 동작이 제대로 안되도록 하는 거라는 걸 확인할 수 있다.
$userID = mysqli_real_escape_string($db,"<script>documnet.cookie();</script>admin");
을 해보면 "admin"만 출력한다는 걸 확인할 수 있다.
패스워드나 아이디 입력한 걸
$password = "password' OR 1='1 --";
$password = preg_replace("/[\s\t\'\;\"\=\-]+/","", $password); // 공백이나 탭 제거, 특수문자 제거
으로 하면 공백 자체를 입력하지 못하게 하여 SQL Injection 공격을 방지할 수 있다.
정규식을 아이디/패스워드 입력용, 검색용 등 각각 별도로 함수를 만들어서 사용하는 게 좋을 것이다.
$str = "<script>documnet.cookie();</script>admin";
$str = preg_replace("/\<script[^\>]*\>(.*?)\<\/script\>/", "", $str); // 스크립트 제거
echo $str.'<br/>';
$str ="<!-- HTML -->주석";
$str = preg_replace("/\<\!\-{2}[^\>](.*?)\-{2}\>/", "", $str); // HTML 주석 제거
echo $str.'<br/>';
?>
플래그(flags)
정규 표현식 리터럴을 작성할 때 플래그를 사용하여 기본 검색 설정을 변경할 수 있다.
|
플래그(flag)
|
설명 |
| i |
검색 패턴을 비교할 때 대소문자를 구분하지 않도록 설정함. |
| g |
검색 패턴을 비교할 때 일치하는 모든 부분을 선택하도록 설정함. |
| m |
Multi line을 표현하며 대상 문자열이 다중 라인의 문자열인 경우에도 검색하는 것을 의미한다.
|
| y |
대상 문자열의 현재 위치부터 비교를 시작하도록 설정함. |
| u |
대상 문자열이 UTF-8로 인코딩된 것으로 설정함. |