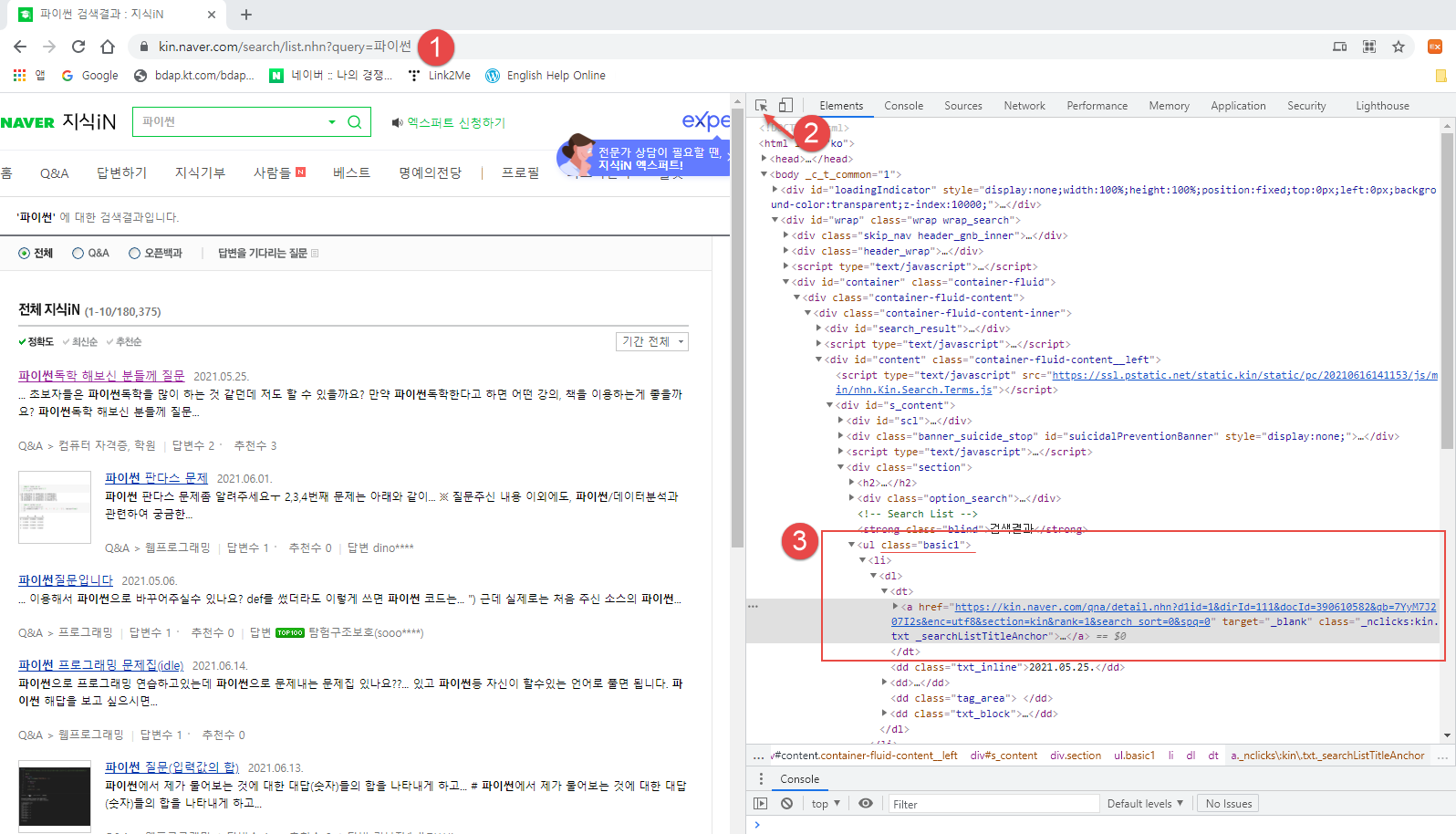
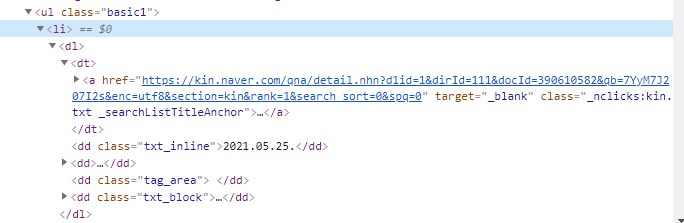
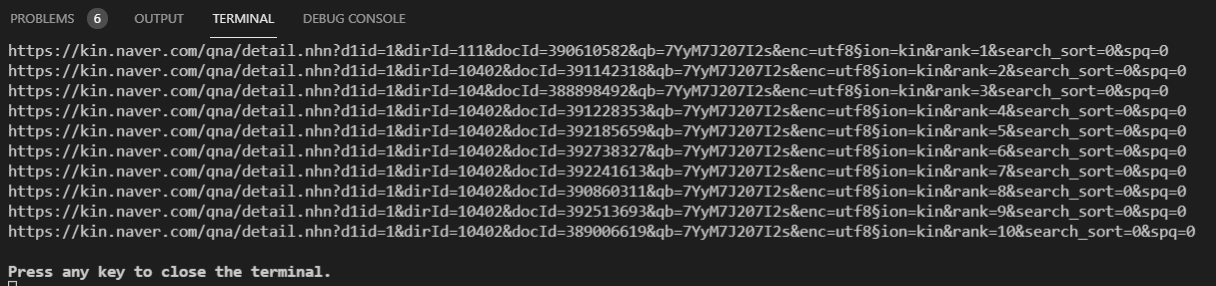
다음 주식 정보 가져오기 예제이다.
Ajax 로 되어 비동기 통신으로 처리된 경우, 간단하게 정보를 가져올 수가 없다.

|
# 다음 주식정보 가져오기
#pip install fake-useragent
import json
import urllib.request as req
from fake_useragent import UserAgent
# Fake Header 정보(가상으로 User-agent 생성)
# Python 으로 정보를 크롤링하지만 마치 웹브라우저에서 실행하는 것처럼 인식하게 만든다.
ua = UserAgent()
# print(ua.ie)
# print(ua.msie)
# print(ua.chrome)
# print(ua.safari)
# print(ua.random)
# 헤더 정보
headers = {
'User-agent': ua.ie,
'referer' : 'https://finance.daum.net'
}
# 다음 주식 요청 URL
url = "https://finance.daum.net/api/search/ranks?limit=10"
# 요청
response = req.urlopen(req.Request(url, headers=headers)).read().decode('UTF-8')
# 응답 데이터 확인(JSON Data)
#print('res',res)
# 응답 데이터 string -> json 변환 및 data 값 출력
rank_json = json.loads(response)['data']
# 중간 확인
#print('중간 확인 :', rank_json, '\n')
for elm in rank_json:
# print(type(elm))
print('순위 : {}, 금액 : {}, 회사명 : {}'.format(elm['rank'],elm['tradePrice'], elm['name']))
|
샘플 코드 작성 파이썬 소스
728x90
'Web 크롤링 > Python Crawling' 카테고리의 다른 글
| [크롤링기초] 네이버 주식 현재가 가져오기 (0) | 2021.06.25 |
|---|---|
| [크롤링기초] 개발자도구 송수신 분석 (0) | 2021.06.23 |
| [크롤링기초] 행정안전부 RSS 정보 크롤링 예제 (0) | 2021.06.22 |
| [크롤링기초] 사이트 정보 확인 (0) | 2021.06.22 |
| [크롤링 기초] lxml 활용한 네이버 지식인 정보 가져오기 (0) | 2021.06.22 |

Link2Me