728x90
주소가 맞는지 검증하여 결과를 엑셀로 반환 저장하는 코드가 필요해서 사용한 코드이다.
|
# pip install selenium # Selenium 설치
# pip install openpyxl # Excel 다루기
# pip install webdriver-manager # Webdriver Manager for Python is installed
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
import time
import pandas as pd
# 크롬 드라이버 생성
options = Options()
#options.add_experimental_option("detach", True) # 브라우저 창 떳다기 사라지기(False), 계속 유지(True)
options.add_argument("headless") # 창 숨기는 옵션
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
# driver.maximize_window() # 브라우저 창 최대로 하는 옵션인데 필요없을 거 같다.
aaa = []
bbb = []
a = pd.read_excel(r'Juso_ErrData.xlsx')
b = pd.DataFrame(a)
c = b['검증주소']
n = 0
g = c.count()
# 사이트 접속하기
url = 'https://www.juso.go.kr/support/AddressMainSearch.do?searchKeyword='
while n < g:
keyword = str(c[n])
print(keyword)
driver.get(url + keyword) # url 페이지로 이동
time.sleep(2) # 로딩 대기
try:
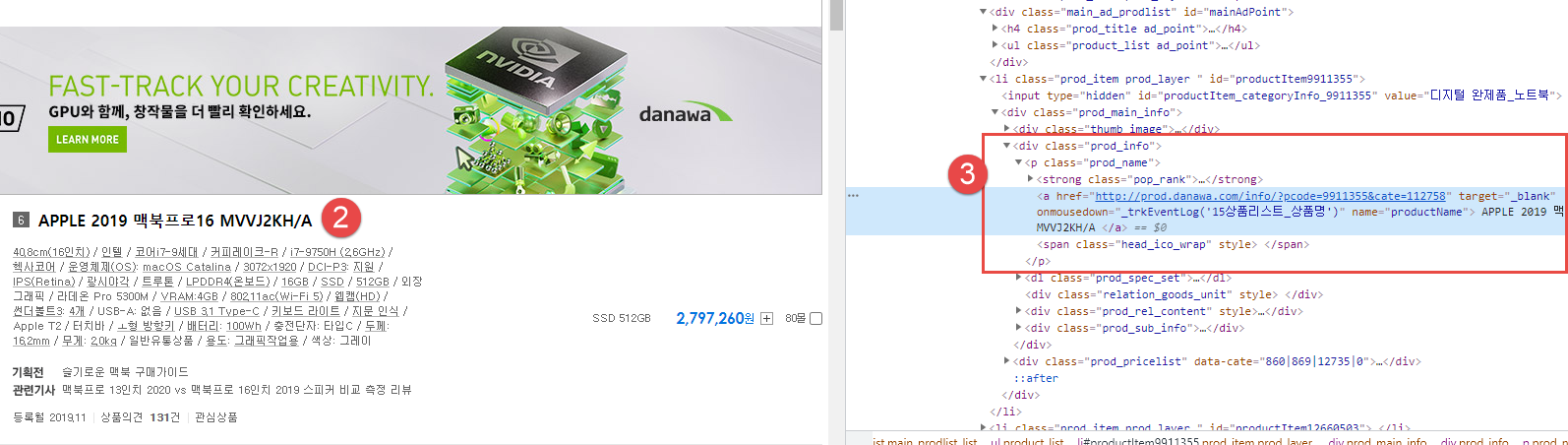
roadAddress = driver.find_element(By.XPATH, value='//*[@id="list1"]/div[1]/span[2]').text
jiAddress = driver.find_element(By.XPATH, value='//*[@id="list1"]/div[2]/span[2]').text
except:
pass
roadAddress = ''
jiAddress = ''
print(roadAddress)
aaa.append(roadAddress)
bbb.append(jiAddress)
n += 1
b['도로명주소'] = aaa
b['지번주소'] = bbb
b.to_excel('보정주소.xlsx', index=False)
|
위 코드 파일과 샘플 엑셀 파일
728x90
'Web 크롤링 > Python Crawling' 카테고리의 다른 글
| 파이썬 selenium CentOS 7 환경설정 및 juso.go.kr 자료 파싱처리 (0) | 2024.03.25 |
|---|---|
| 파이썬 selenium 드라이버 설치 없이 사용하자. (0) | 2024.03.24 |
| 네이버 증권 정보 크롤링 예제 2 - 일별 시세 정보 가져오기 (0) | 2023.03.31 |
| 네이버 증권 정보 크롤링 예제 1 - 상장주식수 가져오기 (0) | 2023.03.26 |
| 파이썬 selenium 활용 네이버 뉴스 스탠드 크롤링 (0) | 2021.06.28 |

Link2Me